
"Data Extraction: Largest Companies in Canada" is a web scraping project that extracts data from a Wikipedia page listing the largest companies in Canada. The project utilizes BeautifulSoup and pandas to collect, structure, and save the tabular data to a CSV file for further analysis and use.

This project focuses on building a highly accurate email spam detection model using a dataset of 5,572 records. By evaluating various classification algorithms and employing evaluation metrics, it aims to enhance email security and efficiency by automatically filtering out unwanted emails.
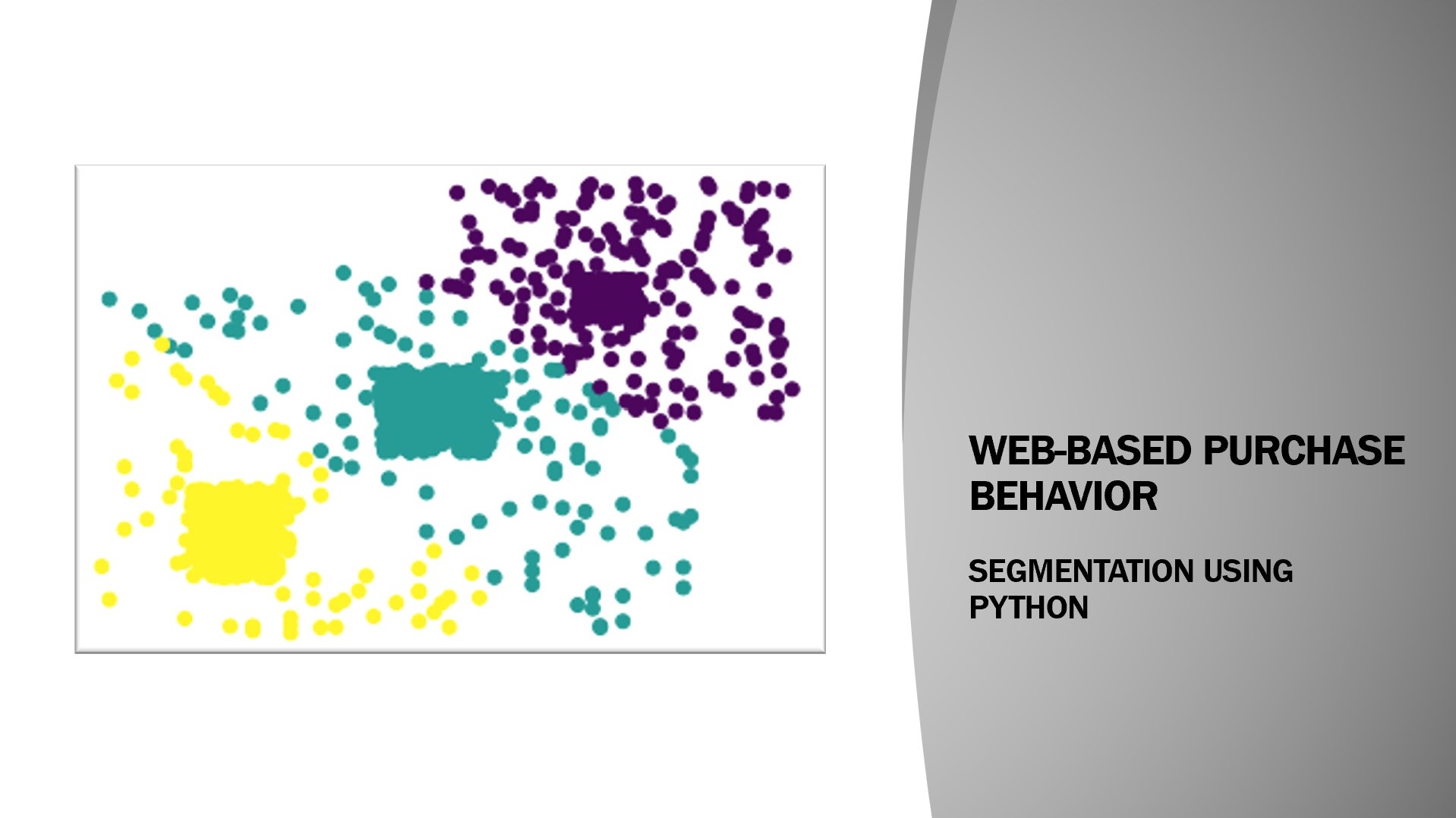
This project utilizes K-Means clustering to segment customers based on their web and purchase behavior. By analyzing variables such as average time spent on the website and average purchase price, distinct clusters emerge, enabling businesses to tailor their marketing strategies and offers to each segment's preferences.
This project utilized regression analysis on housing data to develop prediction models for housing prices. The selected model demonstrated better performance on both the training and test sets, allowing for the prediction of prices for a large dataset of apartments.

This project utilizes decision tree classifiers to analyze voter preferences for the 2016 US Presidential Election. It explores feature selection based on entropy, fits the model using entropy and Gini impurity, determines the optimal depth of the tree, evaluates the model's effectiveness, and visualizes the relationship between '2015 Income' and another chosen feature.

This project focuses on analyzing college admissions data using cross-validation and applying classification models such as logistic regression and support vector machine to predict admission outcomes, with the logistic regression model performing better based on accuracy scores and the confusion matrix evaluation.
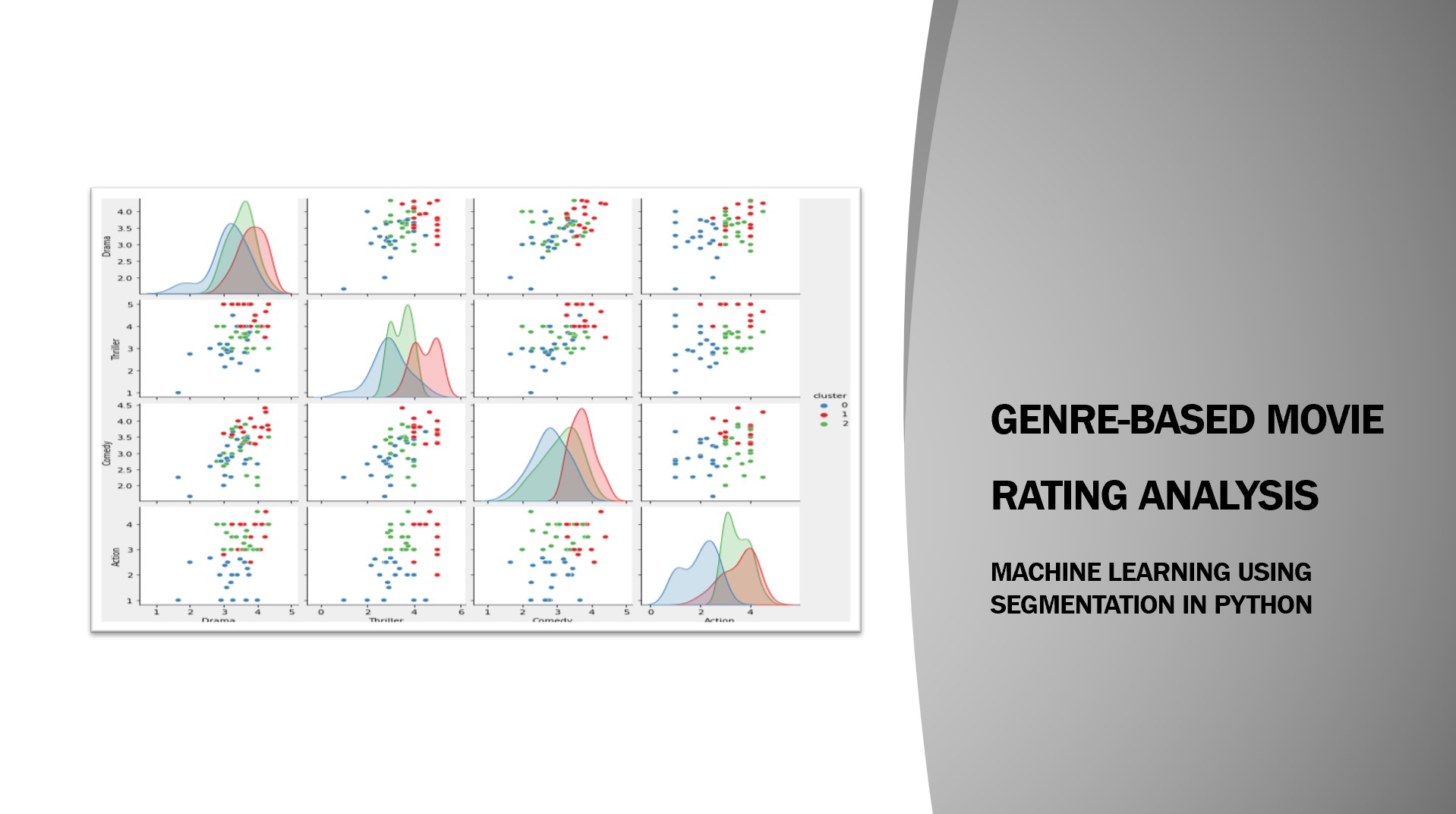
Genre-based Movie Rating Analysis: A Python project that leverages pandas to load and format movie and rating data, allowing for the comparison of average user ratings across different genres. By utilizing data segmentation based on genre, insights can be gained into the variations in ratings for various genres.